这篇笔记主要记载GDA和朴素贝叶斯的概念和推导
高斯判别分析(Gaussian Discriminant Analysis GDA)
这个模型做了两个假设:
GDA模型可表示为:
模型中的参数包括,GDA一般使用同一个协方差矩阵分布:
模型的概率密度表示为:

对数最大似然估计为:

根据导数为零做参数估计得:

Question:感觉这个参数估计需要求导计算么?利用几何意义直接在训练集上统计不就有了么?
最后的结果为:
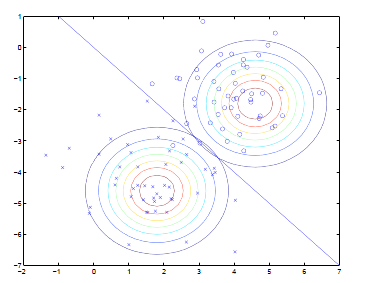
由于假设中两个高斯分布的协方差相同,只是位置不同,所以可以用直线做类别分割
高斯判别分析(GDA)和逻辑回归的关系
使用GDA的密度函数计算Y关于X的概率函数P(Y=1|X)得:
和逻辑回归判别函数的形式是一致的
也就是说如果p(x|y)符合多元高斯分布,那么p(y|x)符合logistic回归模型。反之,不成立。为什么反过来不成立呢?因为GDA有着更强的假设条件和约束。
如果认定训练数据满足多元高斯分布,那么GDA能够在训练集上是最好的模型。然而,我们往往事先不知道训练数据满足什么样的分布,不能做很强的假设。Logistic回归的条件假设要弱于GDA,因此更多的时候采用logistic回归的方法。
朴素贝叶斯(Naive Bayes)
在GDA中,我们要求特征向量x是连续实数向量。如果x是离散值的话,可以考虑采用朴素贝叶斯的分类方法。
可以参考以前的笔记
TODO 继续整理