Context Management Protocol
The
withstatement allows a sequence of statements to execute under the control of another object known as a context manager.
Callable Interface
An object can emulate a function by providing the call(self [,*args [, **kwargs]])method.
class DistanceFrom(object):
def __init__(self, origin):
self.origin = origin
def __call__(self, x):
return abs(x - self.origin)
nums = [1, 37, 101, -20, 9, 13]
nums.sort(key=DistanceFrom(10))
Object String Representatin
__str__(self) create a simple string representation, called by the built-in str() function and by functions related to printing, user can customize the output(if undefined, use __repr__() instead)
__repr__(self) create a string representing the object, called by the built-in repr() function, if possible returns an expression string that can be evaluated to re-create the object, or returns a string in form “<…message…>”
a = [2,3,4] #create a list
a_restore = eval(repr(a)) # restore the list from the 'repr'
f = open("foo")
repr_str = repr(f) # can't re-create, return "<open file 'foo', mode 'r' at dc030>"
__format__(self, foramt_spec) create a formated representation
TODO not clear about this
Object Creation and Destruction
__new__(cls [, *args [, **kwargs]])class method called to create a new instance__init__(self [, *args [, **kwargs]])called to initialize a new instance-
__del__(self)called when an object is being destroyedclass Foo(object): def init(self, para=10): self.x = para
foo1 = Foo(10) # equivalent with below foo2 = Foo.new(Foo) foo2.init(10)
Built-in types for representing Program Structure
In Python, functions, classes, and modules are all objects that can be manipulated as data.
Callable Types objects that support function call operation
-
User-Defined Function : objects created at the module level by using the def statement or with the lambdaoperator.
def foo(x, y): return x+y bar = lambda x, y: x+y
-
Method : Functions that are defined inside a class definition. There are three common types of methods—instance methods, class methods, and static methods:
class Foo(object):
def instance_mothod(self, arg): pass @classmethod def class_method(cls, arg): pass @staticmethod def static_method(arg): pass -
Built-in Functions and Methods : functions and methods implemented in C and C++. like
len()append()
Data Types
None
this null object None
Numbers
int(32bit), long(unlimited range), float(64bit, IEEE 754), complex, bool
immutable
Sequences
str, tuple, list
str and tuple are immutable, while list allow insertion, deletion and substitution
all support iteration
shared operations: s[i], s[i, j], len(s), max(s), min(s), all(s), any(s)
sum(s) sums items in s but only works for numeric data
for mutable list, can use del remove elements: del s[i:j]
Mapping
dict
key must be immutable
Sets
set, frozenset
items must be immutable
First-Class Objects
All objects in Python are “first class”, This means that all objects that can be named by an identifier have equal status. It also means that all objects that can be named can be treated as data.
items = {}
items['func'] = abs
import math
items['module'] = math
nums = [1, 2, 3]
items['append'] = nums.append
# Just use the value in dict
items['func'](-12) # output 12
items['module'].sqrt(100) # output 10.0
items['append'](4) # append '4' to nums
Reference Counting and Garbage Collection
All objects are reference-counted, An object’s reference count is increased whenever it’s assigned to a new name or placed in a container such as a list, tuple, or dictionary
An object’s reference count is decreased by the delstatement or whenever a reference goes out of scope (or is reassigned).
import sys ; sys.getrefcount(a)
Reference and Copies
Any thing in python is
Object
reference copy -> shallow copy --> deep copy
For immutable objects, like numbers and strings, simple reference copy is ok:
a = 10
b = a # b also points to 10
a = 100 # change a, b will not be affected
But for normal objects, like containers or other mutable objects, there will be a ‘problem’:
a = [1,2]
b = a # make a reference copy of a
b[0] = 10 # change b, a will get affected which may not in your will
Then consider the ‘shallow copy’
a = [1,2, [3,4]]
b = list(a) # make a new list that contains all **objects** in a
b[0] = 10 # change immutable objects in b, a will not get affected
b[2][0] = 30 # change mutable objects in b, a will get affected
What if you want a completely copy than no one affects the other? use ‘Deep copy’
import copy
a = [1, 2, [3, 4]]
b = copy.deepcopy(a) # deep copy of a
b[2][0] = 30 # will not affect a
Compare Two objects
def compare(a, b): if a is b: # a and b are the same object pass if a == b: # a and b have the same value pass if typa(a) is type(b): # a and b have the same type pass if isinstance(a, b): # a and b have the same type, inheritance considered
print list of unicode strings
lst = [u'\u00f1', u'\u00ff']
print lst # output not user friendly
print ','.join([i for i in lst])
String
In Python 2 string literals correspond to 8-bit character or byte-oriented data. A serious limitation of these strings is that they do not fully support international charac-ter sets and Unicode.To address this limitation, Python 2 uses a separate string type for Unicode data.To write a Unicode string literal, you prefix the first quote with the letter “u”. For example:
s = u"Jalape\u00f1o"
In Python 3, this prefix character is unnecessary (and is actually a syntax error) as all strings are already Unicode. Python 2 will emulate this behavior if you run the inter-preter with the -Uoption (in which case all string literals will be treated as Unicode and the u prefix can be omitted).
TODO 比较上面二者的效率
字符串去除空格,回车,tab:
''.join('a A c'.split())'a A c'.replace(' ', '').replace('\n', '').replace('\t', '')
Basic Usage
#python code
f = open("d://test.txt", "w")
print >>f, "Write to file directly"
print >>f, "Formate output %2d-%0.3f" % (1, 1.2131)
# Simple iterate on any containers
for line in open("d://test.txt", "r"):
print line
# terminate program
raise SystemExit(0)
Generator
Any function that uses ‘yield’ statement
Calling a generator function cre-ates an object that produces a sequence of results through successive calls to a next() method
The next() call makes a generator function run until it reaches the next yield state-ment. At this point, the value passed to yield is returned by next(), and the function suspends execution.
def cntdown(n):
while n>0:
yield n
yield '...'
n -= 1
gen = cntdown(10)
print gen.next(), gen.next()
for next in gen:
print next
Generators are an extremely powerful way of writing programs based on processing pipelines, streams, or data flow.
This python version of grep is as follow:
def grep(lines, searchtext):
for line in lines:
if searchtext in line:
yield line
Coroutines
Also a ‘Generator’, but it processes a sequence of inputs sent to it
It uses (yield) expression
def print_match(matchtext):
print 'Looking for %s' % matchtext
while True:
line = (yield)
if matchtext in line:
print line
matcher = print_match('python')
matcher.send('python is coooooool')
matcher.close()
Implementation of Set and Dict
http://svn.python.org/view/python/trunk/Objects/setobject.c?view=markup
Difference bettween str() vs repr()
http://stackoverflow.com/questions/1436703/difference-between-str-and-repr-in-python
Python re模块
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
1. 正则表达式语法
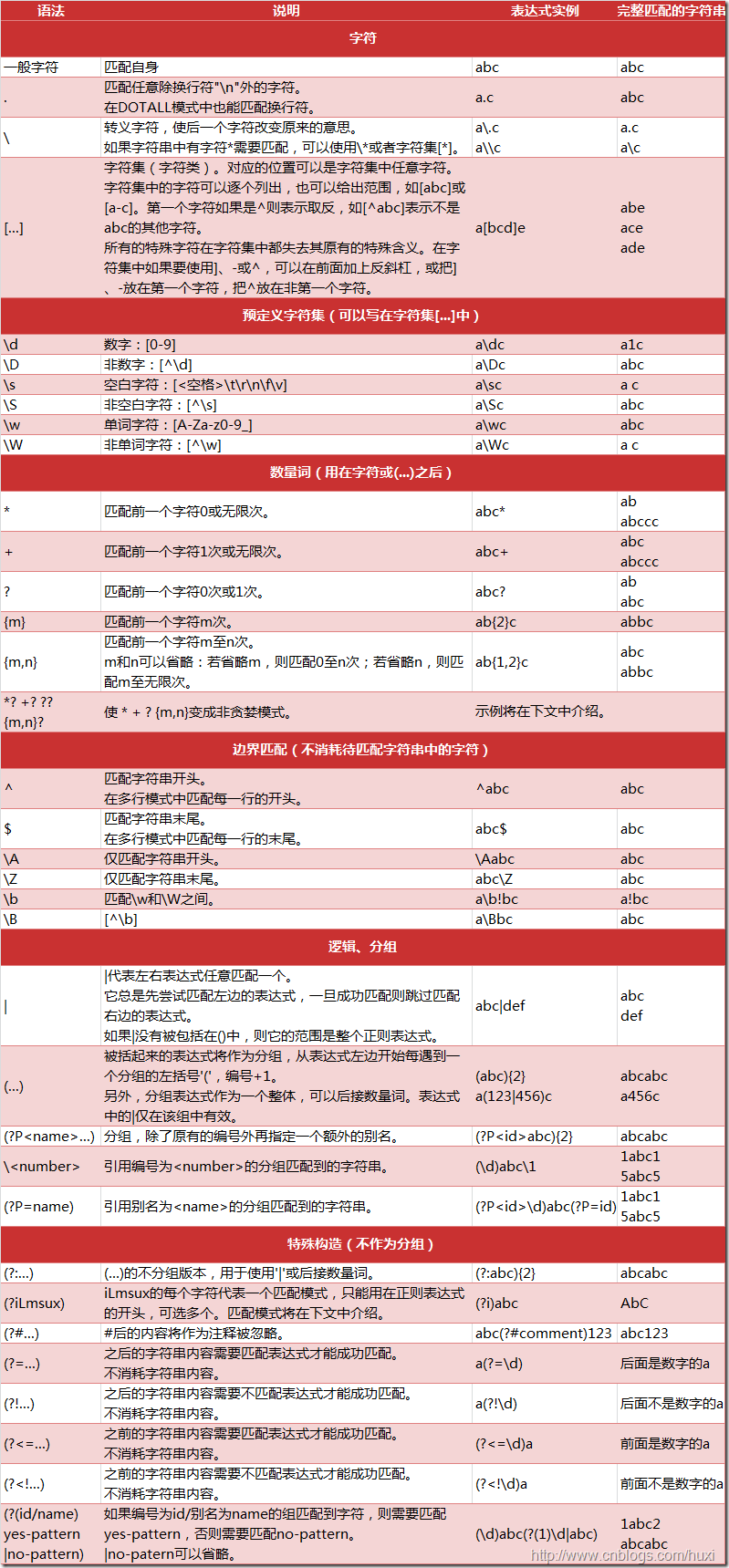{kind=link}
2. 模块内容
re模块中包含一些变量,方法和一个异常,常用的方法如下:
最基本的是re.compile(pattern, flats=0),该方法将正则表达式pattern编译成class re.RegexObject,RegexObject对象包括很多方法,包括:
- 查找方法
search(string [, start_pos [, end_pos]]),在string中查找和正则表达式匹配的子串,找到了返回一个MatchObject,否则返回None - 匹配方法
match(string, [, start_pos [, end_pos]]),匹配string的开头是否匹配正则表达式,如果匹配,返回这个MatchObject,否则返回None - 切分方法
split(string, max_split=0) - 查找所有方法
findall(string [, start_pos [, end_pos]]),以列表的形式,返回在string中匹配到的所有非重合子串 - 迭代查找所有方法
finditer(string, start_pos [, end_pos]], Return an iterator yielding MatchObject instances over all non-overlapping matches for the RE pattern in string. - 替换方法
sub(replacement, string, count=0),将正则表达式在string中匹配到的非重复子串替换为replacement并返回,cont选项设置最大替换个数,默认0表示不限制 - 替换方法
subn(replacement, string, count=0),和sub`类似,只是返回一个tuple(new_string, replace_count)
上面提到的这些方法,都在re包中有对应的静态方法:
re.search(pattern, string, flags=0)re.search(pattern, string, flags=0)re.match(pattern, string, flags=0)re.split(pattern, string, max_split=0, flags=0)re.findall(pattern, string, flags=0)re.finditer(pattern, string, flags=0)re.sub(pattern, repl, string, count=0, flags=0)re.subn(pattern, repl, string, count=0, flags=0)
re包还有一些其他方法:
re.escape(string), 对string中的非字母数字进行转移(前面加上反斜杠)re.purge(),清空re的缓存
发现re包中的方法都带有flag,这些参数有来配置各种选项,常用的flag选项有:
re.DEBUG这样会输出一些debug的信息re.Ii.e.re.IGNORECASE忽略大小写re.Li.e.re.LOCALE本地化,使\w, \W, \b, \B, \s and \S匹配当前语言环境的字符re.Mi.e.re.MULTILINE使^,$分别匹配每行的开始和结束re.Si.e.re.DOTALL使.匹配任意字符,默认情况下,.匹配除换行符外的字符re.Ui.e.re.UNICODE使\w, \W, \b, \B, \d, \D, \s and \Sdependent on the Unicode character properties database.re.Xi.e.re.VERBOSE使正则表达式写起来更优雅,比如默认忽略空格,可以使用#添加注释
说到MatchObject对象,其保存了匹配结果
最重要的一个方法是group([group1, group2,...]),其中的参数有多种形式,直接是捕获组的ID,如group(2),也可以是几个组ID,group(1,3),如果有命名捕获组,可以是捕获组的名字,group("name")
还有一个常用方法是groups([default]),用来把所有的捕获组放到tuple中输出
参考
install numpy on windows
just use exe installer
easy_install & pip to install python packages
-
use
pip uninstall <package>to remove package -
use
pip freezeto list installed packages
file encoding etc.
Rather than mess with the encode, decode methods I find it easier to use the open method from the codecs module.
import codecs
f = codecs.open("test", "wr", "utf-8")
var = u'test:\u7b2c1\u9875:\u9664\u4e86\u623f\u8fd8\u662f\u623f'
f.write(var)
f.flush()
f.read()
语言规范
TODO