本篇笔记主要记载监督学习基本概念,及回归问题的概念和推导
监督学习
监督学习:通过学习带标签的训练数据,学习如何预测未知数据的标签问题
对于训练数据集 train-set:
学习得到一个函数h,给定x,能较好地c预测y,即:,
过程如下图所示:
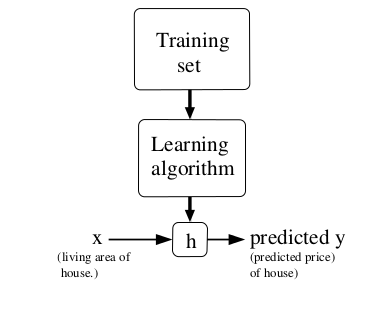
当预测目标变量(即y)是连续变量时,该问题称为回归问题;当目标变量取有限个离散值时,该问题称为分类问题
先引出一个具体问题:房价预测
训练集包括部分已知房价的房子的两个feature:面积和卧室数量;学习目标函数h能通过房子的面积和卧室数量,预测房价。
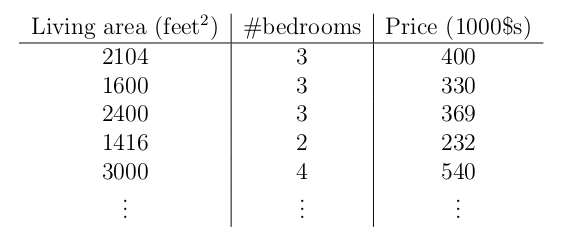
约定符号如下:
- 训练数据个数: m
- feature 个数: n
- 表示:第i条训练数据的第j个属性feature
线性回归
为了学习预测函数,首先应该确定如何表示h,线性回归做了一个最简单的假设:y是关于x的线性函数
其中,是参数,也称权重。为了简化表示,令,则有:
现在我们需要通过训练集学习参数,一个简单合理的方法是使h(x)在训练集上接近y,以此,我们定义代价方程(Cost Function)为:
我们的目标就是求解优化问题:
1. LMS(Least Mean Square 最小均方)算法
搜索求解上面的最小化问题,开始初始化(比如),不断改变的值,使变小
2. The Normal Equations 等式求解
该方法不再像最小均方法一样迭代求解,而是直接令导数为0求极值,即求解
向量表示J为:
计算梯度为:
其中,第三步中,‘标量’的导数等于其秩的导数;第四步中,去掉了常数项;第五步合并相等的两个秩;第七步参考这里这里
令梯度为0得:
可以直接通过上式求解最优解,但存在几个问题:
- 公式中存在矩阵求逆操作,时间复杂度很高,不适合大数据下求解
- 求逆要求矩阵非奇异,尤其对于稀疏数据来说,需要注意这点
概率角度解释最小平方代价函数的合理性
假设对于每个目标变量y和自变量x,存在如下关系:
其中是误差,我们可以进一步假设独立同分布于高斯分布:
则有:
则有:
其中, 表示 关于 的条件概率, 是参数,而不是变量!
在训练数据集上使用极大似然估计得:
由于包含指数连乘,所以使用对数似然函数:
这样:
这也是最小二乘的代价方程!
注意,概率模型中做了几个假设,但这些假设并不是论证最小二乘代价方程正确性所必须的,同时,论证过程和假设的高斯分布的方差无关!
局部加权线性回归(Locally Weighted Linear Regression)

上图中的点明显不是线性函数生成的,假如我们用线性回归去模拟,如红线所示,并不能完全和数据吻合,有很多点都落在了置信区间之外(红线两边的灰色地带),导致预测准的下降
假如我们对x=2.5处的点进行预测,如果只是用区间[2,3]之间的数据点,效果如图中蓝色线,效果非常好,这就是局部回归的思想
在局部回归中,对某点进行预测仅仅选择其临近区域的样本,而其他样本则被浪费了,不免可惜,而且对该区域作回归时在临近区域内的样本对预测结果的影响是一样大的,一个更合理的想法是一个样本离某点越近,对该点的影响越大,这就引出了局部加权回归。 具体的做法是,在损失函数中加入权数,离目标点越近,权数越大:
其中,是波长参数(bandwidth parameter),控制权数随距离下降的速度
局部回归有点如上所示,缺点: 1. 每次对一个点的预测都需要整个数据集的参与,样本量大且需要多点预测时效率低。提高效率的方法参考Andrew More的 KD Tree 2. 不可外推,对样本所包含的区域外的点进行预测时效果不好,事实上这也是一般线性回归的弱点