In statistics and machine learning, ensemble methods use multiple models to obtain better predictive performance than could be obtained from any of the constituent models.
基本思路如下图所示:
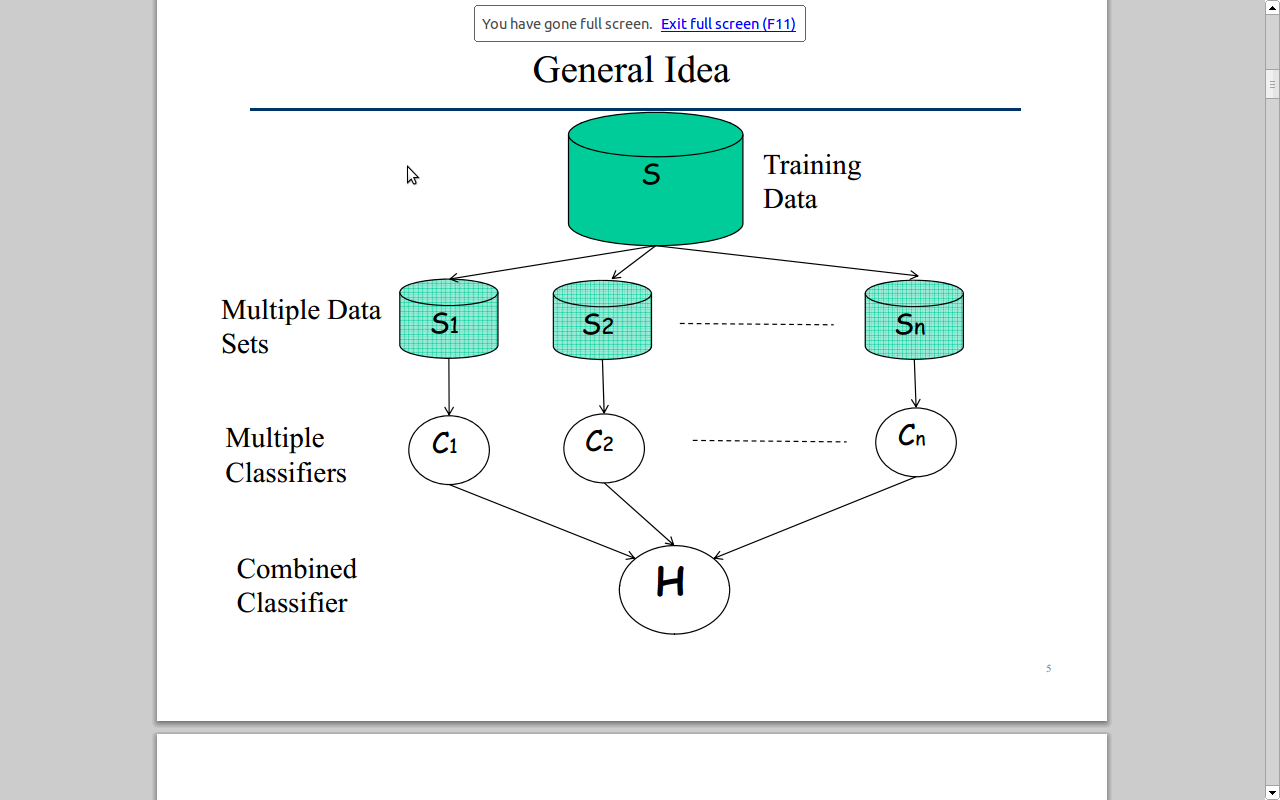
简单说,就是训练多个模型,根据每个模型的投票做预测
- 优点: 提高预测性能,直接级联不同模型,容易实现,参数较少
- 不足:多个模型混合在一起是预测结果不可理解,黑盒系统
提高预测性能的原因解释,假设有N个基本分类器,每个分类器的出错率是,假设各个分类器独立,那么集成分类器的出错率为:
其远远小于单个分类器的出错率
常见的集成学习方法有:Bootstrap Aggregating(缩写为Bagging),提升算法 Boosting,随机森林 RandomForest
Bootstrap Aggregating(Bagging)
首先理解Bootstrap,名字来自成语“pull up by your own bootstraps”,意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法
- 训练:每个基本分类器通过从数据集中随机出一部分学习得来
- 预测:每个分类器投票,之后多数表决
提升算法 Boosting
提升(boosting)算法是一种常用的统计学习方法,在分类问题中,通过改变分类样本的权重,学习多个分类器,并将这些分类器组合,提高分类性能。
比较著名的提升算法有提升树模型(Boosting Tree)和自适应提升算法AdaBoost(Adaptive Boosting),提升树模型是以决策树为基函数的提升算法,算是Adaboost的一种特例吧,下面主要介绍Adaboost算法
对于提升算法,有两个重要问题:1. 每一轮如何改变数据的权值或概率分布 2. 如何将几个弱分类其组合成强分类器
- 对于问题1, AdaBoost的做法是,提高在前一轮中被错分的数据样本的权值,这样被错分的数据得到更大关注
- 对于问题2, AdaBoost的做法是,加权多数表决,即加大分类误差率小的分类器权值,使其在表决中起较大作用
不改变所给训练数据,而不断改变训练数据的权值分布,使得训练数据在基本分类器的学习中起到不同作用,这是Adaboost的特点
理论基础:
在概率近似正确(Probably Approximately Correct, PAC)框架中,有两个概念:
- 强可学习:对于一组概念,如果存在多项式复杂度的算法能学习它,且正确率很高,就称其为强可学习的
- 弱可学习:对于一组概念,如果存在多项式复杂度的算法能学习它,学习效果只比随机算法略好,则称其为弱可学习的
后证明,在PAC框架下,强可学习和弱可学习是等价的,这也就意味着,可以组合多个弱分类器,构成强分类器
学习过程:
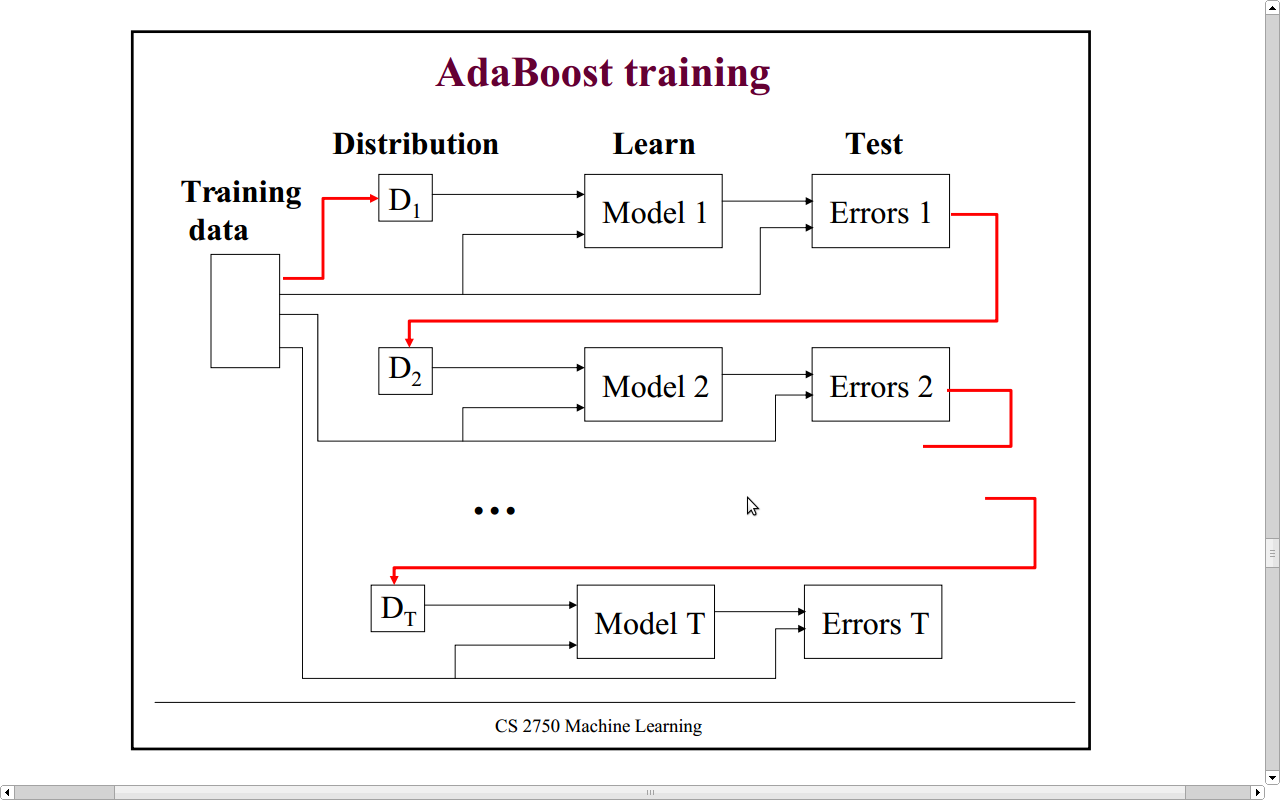
算法描述:
输入:弱学习算法以及训练数据,其中,实例,标记
输出:强分类器G(x)
1 初始化权值分布
2 训练M个弱分类器,对于m=1,2,..,M
(1) 根据当前权值分布,训练数据,得基本分类器 (2) 计算在训练数据集上的带权分类误差率
(3) 计算的系数
(4) 更新训练数据权值分布
这里,是归一化因子,使得成为一个概率分布
3 构建基本分类器的线性组合得最终分类器为:
另一种解释:
AdaBoost算法可以看作是:模型是加法模型,损失函数是指数函数,学习算法是分步向前算法时的二类分类算法