哈希及其应用
- 哈希表(Hash table,也叫散列表)
- 根据关键码值(Key value)而直接进行访问的数据结构
- 冲突解决策略
- Chaining: 当多个不同的key被映射到相同的slot时,chaining方式采用链表保存所有的value
- Open addressing: 在该slot的邻近位置查找,直到找到对应的value或者空闲的slot, 这个过程被称作探测(probing)。常见的探测策略:
- 线性探测 Linear probing 可能产生聚集
- 二次探测 Quadratic probing 可能产生二次聚集?
- 双散列 Double hashing 第二个散列函数选择很重要
- 再散列
- 当哈希表装载因子大于阈值时,建立更大的哈希表,将原有数据哈希进去
- 对于Chaining,装载因子阈值为0.75左右
- 对于open addressing,装载因子阈值为0.5左右
- 使用再散列的另外一种情况是减小哈系表长
- 当哈希表装载因子大于阈值时,建立更大的哈希表,将原有数据哈希进去
- 哈希 vs 二叉查找树
- 散列在常数时间内实现find和insert操作,但不能找最小,最大
- 二叉查找树在O(logN)下实现find和insert操作,且不需要做乘法除法
- O(logN)并不比O(1)大很多
- 数据有序输入会使普通二叉排序树性能变得很差,而平衡查找树的实现代价很高,如果不需要有序信息以及输入数据没有排序,尽量不要使用之
- Perfect hashing 完美哈希
- 没有冲突的哈希函数
- 函数 H 将 N 个 KEY 值映射到 M 个整数上,这里 M>=N ,而且,对于任意的 KEY1 ,KEY2 ,H( KEY1 ) != H( KEY2 ) ,并且,如果 M = = N ,则 H 是最小完美哈希函数(Minimal Perfect Hash Function,简称MPHF)
- 完美哈希是针对静态集合的,即所有的key都是事先已知且固定的
- 完美哈希有多种代码生成器,根据key集合自动生成哈希函数,如gperf
- 大数据下应用
- 分段+哈希:有份文件,包含10亿个int数字,找出重复出现过的数字,而内存限制是32M,如何做?
- int的范围是[-2^31 , 2^31-1 ],共2^32 -1 个,int的大小是4字节,那么,如果使用普通哈希的话,需要内存:(2^32 -1)*4B ~ 16GB,这对于普通机器是无法容忍的
- 数据都是int类型的,比较容易实现完美哈希(即每个int值直接模上哈希表长度作为其在哈希表中的位置),所以可以使用一个比特位来标识这个数字是否以出现过(类似基数排序的思想),如果使用位图来存,存下所有int数字还是需要:(2^32-1)bite ~ 512M,依然太大了
- 32M内存,我们拿出16M作为哈希,使用位图可以表示128M个数字,我们将int数从小到大切分,每份128M个数字,共2^5 =32份,这样一份份比较,就把问题解决了(桶排序的思想),具体说,把大文件切分成32个小文件,第i个文件中存放[(i-1)2^27 ~i2^27]之间的数字,之后分别统计每个文件中是否有重复数字即可~
- 这个题目还有另外一个思路,把int范围内的数做成哈希,显然需要的内存太大了,想到布隆过滤器就是专门解决这种问题的,布隆过滤器在保证误判率较低的情况下大大减小哈系空间
- 分段+哈希:有份文件,包含10亿个int数字,找出重复出现过的数字,而内存限制是32M,如何做?
Locality-Sensitive Hashing(LSH)
关于相似哈希,严重推荐参考这里,比自己做的笔记清楚多了==!
传统hash函数解决的是生成唯一值,比如 md5、hashmap等。md5是用于生成唯一签名串,只要稍微多加一个字符md5的两个数字看起来相差甚远;hashmap也是用于键值对查找,便于快速插入和查找的数据结构。不过我们主要解决的是文本相似度计算,要比较的是两个文章是否相识,当然我们降维生成了hashcode也是用于这个目的
相似哈希的核心思想:相似数据的哈希签名也相似
相似哈希在网页去重中有两个优势,:
- 将网页转化为较短的相似哈希签名(一方面压缩了数据,同时保存了原始网页间的相似信息)
- 快速查找相似网页(最近邻查找),这样网页去重时,就不需要遍历所有网页(的哈希签名)计算相似度,而是直接找被哈希到一个桶中的网页
- 计算哈希签名的相似度比计算原始网页的相似度要简单快速
TODO 机器学习中数据降维 直觉上觉得,相似哈希通过计算原始数据的哈希签名,降低了数据维度,和PCA(SVD)做的工作异曲同工,有时间再考究一下
相似哈希的实现,主要包括两点:
- 相似哈希签名计算方法,
- 哈希签名的相似度计算方法
相似哈希是一种思想,主要有下面几种实现:
- 随机超平面哈希 Random projection hash
- 相似哈希 simhash(Bit sampling for Hamming distance)
- 最小哈希 minhash(Min-wise independent permutations)
随机超平面映射 Random Projection
随机超平面hash算法非常简单,对于一个n维向量v,要得到一个f位的签名(f«n),算法如下:
1. 随机产生f个n维的向量r1,…rf;
2. 对每一个向量ri,如果v与ri的点积大于0,则最终签名的第i位为1,否则为0.
这个算法相当于随机产生了f个n维超平面,每个超平面将向量v所在的空间一分为二,v在这个超平面上方则得到一个1,否则得到一个0,然后将得到的f个0或1组合起来成为一个f维的签名。如果两个向量u, v的夹角为θ,则一个随机超平面将它们分开的概率为θ/π,因此u, v的签名的对应位不同的概率等于θ/π。所以,我们可以用两个向量的签名的不同的对应位的数量,即汉明距离,来衡量这两个向量的差异程度。
choosing k random vectors r_i in the given feature vector space, and defining k one bit hash functions as follows: h_i(v) = 1, if dot(r_i, v) >= 0 h_i(v) = 0, if dot(r_i, v) < 0 The k-bit sketch is then trivially arrived at by passing a vector v through each of the k hash functions and concatenating the resulting bits.
simhash
simhash是Charikar 在2002年提出来的,参考 《Similarity estimation techniques from rounding algorithms》,谷歌网页去重就使用的是这个simhash
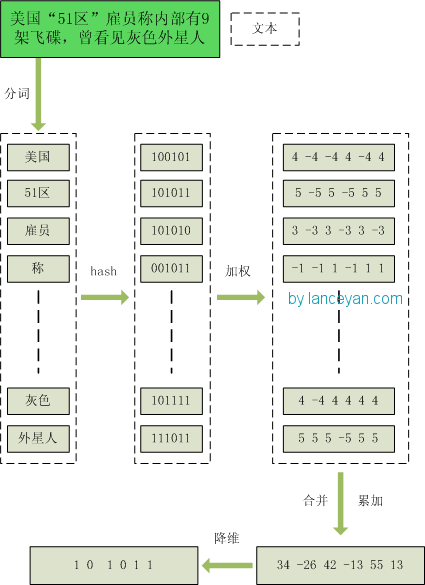
对文本数据做simhash的过程如下:
- 分词,去掉停用词,确定词的权重(权重表示词对文档的重要程度,可以用词频)
- 哈希,将每个词映射为向量,要求每个词映射后的向量随机分布,且不同词对应的向量不同,因此使用一般的哈希方法即可
- 加权,将每个词的哈希签名h看做01串,设词的权重为w,则签名的第k位加权为
h(k) = h(k)==1?w:-w - 合并,将文档中所有词的加权签名按位累加
- 降维,
h(k) = h(k)>0:1?0
过程图如下:
现在,已经得到了计算文档相似哈希签名的方法,计算签名相似度的方法就更简单了,直接计算哈系签名的海明距离,即两个01串的异或
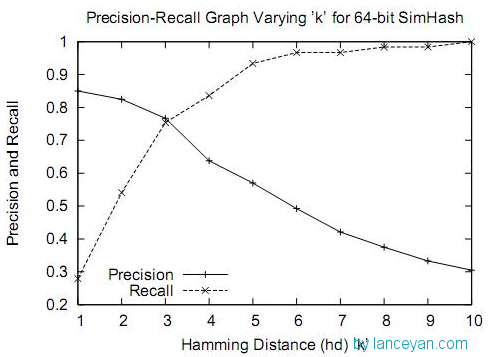
通过大量测试,simhash用于比较大文本,比如500字以上效果都还蛮好,距离小于3的基本都是相似,误判率也比较低。但是如果我们处理的是微博信息,最多也就140个字,使用simhash的效果并不那么理想。
Simhash算法与随机超平面hash是怎么联系起来的呢?在simhash算法中,并没有直接产生用于分割空间的随机向量,而是间接产生的:第k个特征的hash签名的第i位拿出来,如果为0,则改为-1,如果为1则不变,作为第i个随机向量的第k维。由于hash签名是f位的,因此这样能产生f个随机向量,对应f个随机超平面。
simhash算法其实与随机超平面hash算法是相同的,simhash算法得到的两个签名的汉明距离,可以用来衡量原始向量的夹角。这其实是一种降维技术,将高维的向量用较低维度的签名来表征。衡量两个内容相似度,需要计算汉明距离,这对给定签名查找相似内容的应用来说带来了一些计算上的困难;我想,是否存在更为理想的simhash算法,原始内容的差异度,可以直接由签名值的代数差来表示呢?
最小哈希 min-wise independent permutations
问题: 有100w份文件,找相似文档
最小哈希做法:
- 将文档表示成集合:抽取文档中的短字符串集合–Shingling
- 保持相似度的集合摘要:最小哈希
- Shingling集合非常大,将文章表示成shingle集合后,一般都会变大,即使将shingle哈希成4个字节,所占空间仍为原来的4倍左右
- 首先对集合表示成特征矩阵,每列表示一个集合,每行表示一个shingle元素,我们的目标是计算每列之间的相似性
- 对特征矩阵进行行变换,每一列的最小哈希值为该列第一个不为0的行号
- 重复上面步骤n=100~200次,没列得到n个哈希值,组成一个最小哈希签名
- 对大规模特征矩阵进行显式行变换是不可行的
- 可以使用随机哈希函数来模拟矩阵行变换的过程
参考
1. Locality Sensitive Hashing
1. 海量数据相似度计算之simhash和海明距离
2. 文本去重之SimHash算法