最小二乘
最小二乘法又称最小平方法,是一种优化方法,其主要思路是最小化残差的平方和,残差是观测数据和预测值之间的差值
“Least squares” means that the overall solution minimizes the sum of the squares of the errors made in the results of every single equation.
The most important application is in data fitting. The best fit in the least-squares sense minimizes the sum of squared residuals, a residual being the difference between an observed value and the fitted value provided by a model.
上面是从维基百科上摘录的关于最小二乘的描述
When the observations come from an exponential family and mild conditions are satisfied, least-squares and maximum-likelihood estimates are identical.
这就是为啥逻辑回归使用极大似然估计和最小二乘方法不谋而合的原因,更多参考[这里](Charnes, A.; Frome, E. L.; Yu, P. L. (1976). “The Equivalence of Generalized Least Squares and Maximum Likelihood Estimates in the Exponential Family”. )
分类器评估
以二分类器为例
评估分类器可信度的一个基本工具是混淆矩阵(confusion matrix),保存了预测分类和真正分类的关系表格
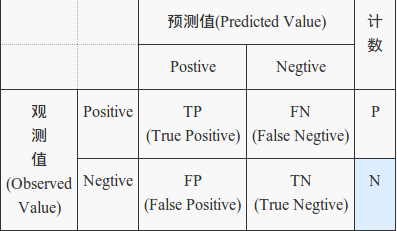
几个常用指标:
-
TP rate(真阳率):
-
FP rate(假阳率):
-
Precision(准确率) : 预测值是Positive的集合中,真正是Positive的比例,
-
Recall(召回率): 观测值为Positive的集合中,被正确判定为Positive的比例,
-
Accuracy(精度): 预测正确的比例,
-
F值:融合准确度和召回率,
上图这些都属于静态的指标,当正负样本不平衡时它会存在着严重的问题。极端情况下比如正负样本比例为1:99(这在有些领域并不少见),那么一个基 准分类器只要把所有样本都判为负,它就拥有了99%的精确度,但这时的评价指标是不具有参考价值的。
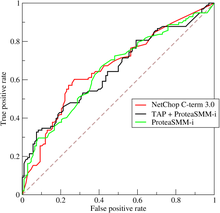
另外就是,现代分类器很多都不是简单地给出一个0或1的分类判定,而是给出一个分类的倾向程度,比如贝叶斯分类器输出的分类概率。对于这些分类器,当你取不同阈值,就可以得到不同的分类结果及分类器评价指标,依此人们又发明出来ROC曲线以及AUC(曲线包围面积)指标来衡量分类器的总体可信度。
ROC曲线最初源于20世纪70年代的信号检测理论,描述的是分类混淆矩阵中FPR-TPR两个量之间的相对变化情况。如果二元分类器输出的是对正 样本的一个分类概率值,当取不同阈值时会得到不同的混淆矩阵,对应于ROC曲线上的一个点。那么ROC曲线就反映了FPR与TPR之间权衡的情况,通俗地 来说,即在TPR随着FPR递增的情况下,谁增长得更快,快多少的问题。TPR增长得越快,曲线越往上屈,AUC就越大,反映了模型的分类性能就越好。当 正负样本不平衡时,这种模型评价方式比起一般的精确度评价方式的好处尤其显著。一个典型的ROC曲线如下图所示:
坐标下降(上升)法
比如优化这个问题: ,坐标下降的过程:
即,每次只将W看作的函数,进行求导优化,而其他的视为常数
优化过程如下图:
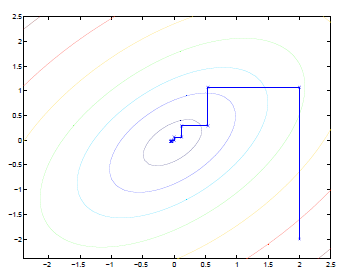
椭圆代表了二次函数的各个等高线,变量数为2,起始坐标是(2,-2)。图中的直线式迭代优化的路径,可以看到每一步都会向最优值前进一步,而且前进路线是平行于坐标轴的,因为每一步只优化一个变量。
凸优化问题
$$
\begin{aligned}
\min_{w} ~& f(x)
s.t.~& g_i(w) \leq 0, i=1,2,…,N
&h_i(x)=0, i=1,2,…,M
\end{aligned}
$$
其中,f(x)和g(w)是R^N 上的连续可微凸函数,h(w)是R^N 上的仿射函数,即满足
当目标函数f(x)是二次函数,约束函数g(x)是仿射函数时,上述凸最优化问题成为凸二次规划问题
VC维理论
对一个指示函数集,如果存在h个样本能够被函数集中的函数按所有可能的2^h种形式分开,则称函数集能够把h个样本打散,函数集的VC维就是它能打散的最大样本数目h。
VC维反映了函数集的学习能力,VC维越大则学习机器越复杂,所以VC维又是学习机器复杂程度的一种衡量。
还不是很明白,感觉VC维就像是分类函数中的参数个数相关
数据倾斜(unbalanced)
- 参与分类的类别样本数量差异很大
- 比如说正类有10,000个样本,而负类只给了100个
- 当考虑离群点而添加惩罚因子的时候,如果存在数据倾斜,不同类别样本的惩罚因子系数应不同,如正比于该类别样本数量
非度量方法(nonmetric method)
- 数据本身没有数值特征,或者说都是‘语义数据’
- 如:<红色,有光泽,甜味,大>, <黑色,无光泽,甜味,小>…
- 上面的表述方法就是描述语义数据的’属性d-元组‘方法,另外一种常见描述方法是直接串起来,如:红色有光泽甜味大
- 如果对这些数据进行分类,常使用判定树
岭回归(RidgeRegression) and 套索回归(LASSO)
- 为了控制模型的复杂度,需要对模型中用到的变量进行控制,其中的一种方法就是Regularization
- Regularization一般又分为L1和L2(cost function上的惩罚项)
- L1为Lasso(Least absolute shrinkage and selection operator),也就是常说的套索
- L2为Ridge Regression,就是常说的“岭回归”
- 注意L1有sparse的特性,参考这里
二次规划
一类特殊的非线性规划,目标函数是二次函数,约束条件是线性的,一般形式:
$$
\begin{align}
\min f(x) &= \min~(\frac{1}{2}x^TQx+c^Tx)
&s.t. Ax<b
\end{align}
$$
正定矩阵
- 正定二次型 对于非零的向量取值恒大于0的二次型
- 设是一个二次型,如果对于任何x!=0,都有Q(x)>0,则为正定二次型
- 正定二次型Q中的矩阵A的特征值全部大于0
- 半正定二次型 取值大于等于0,A的特征中大于等于0
- 正定矩阵 可以构成正定二次型的矩阵(上面的A)
- 正定矩阵的特征值都大于0
最大熵原理
- 学习怪率模型时,在所有可能的概率模型集合中,熵较大的模型较好
- 直观说,首先模型要满足约束条件,不确定的部分使用‘等可能’假设
最大方差理论
- 在信号处理中认为信号具有较大的方差,噪声有较小的方差,信噪比就是信号与噪声的方差比,越大越好。
拉格朗日乘数
- 将有n个变量,k个约束条件的最优化问题转化为n+k个变量的方程组极值问题,其变量‘不受约束’
- 该方法引入新的标量未知数,称为拉格朗日乘数,要求大于0
- 简单例子:
- 优化问题:
- 拉格朗日函数为: 其中
- 新问题为:
- 新问题对x和求导,得到关于x的方程组,求解
松弛求解
在实验数据处理和曲线拟合问题中,求解超定方程组非常普遍。这时常常需要退一步,将线性方程组的求解问题改变为求最小误差的问题。形象的说,就是在无法完全满足给定的这些条件的情况下,求一个最接近的解
比较常用的方法是最小二乘法。最小二乘法求解超定问题等价于一个优化问题,或者说最小值问题,即,在不存在使得的情况下,我们试图找到这样的x使得最小,其中表示范数。
模拟退火(SA,Simulated Annealing)
模拟退火是一种贪心算法,但是它的搜索过程引入了随机因素
模拟退火算法以一定的概率来接受一个比当前解要差的解,因此有可能会跳出局部的最优解,达到全局的最优解。
这个概率随着时间推移逐渐降低,这样才能趋于稳定
区别于爬山算法(Hill Climbing),爬山算法是一种简单的贪心搜索算法,该算法每次从当前解的临近解空间中选择一个最优解作为当前解,直到达到一个局部最优解。
MachineLearning vs DataMining
A lot of common topics: Clustering, Classification…
- ML focuses more on theory
- DM focuses more on applications, efficiency
幂定律(包括zipf定律和80/20法则) , 马太效应
- 幂定律,表现为一条斜率为负幂指数的直线,这一线性关系是判断给定的实例中随机变量是否满足幂律的依据
- zipf定律,把单词出现的频率按由大到小的顺序排列,则每个单词出现的频率与它的名次的常数次幂存在简单的反比关系
- 80/20法则,20%的人口占据了80%的社会财富
- 上面二者都是幂定律的表现形式
- 马太效应,描述富者愈富的现象,富者愈富的现象使得人们的收入呈现为幂分布