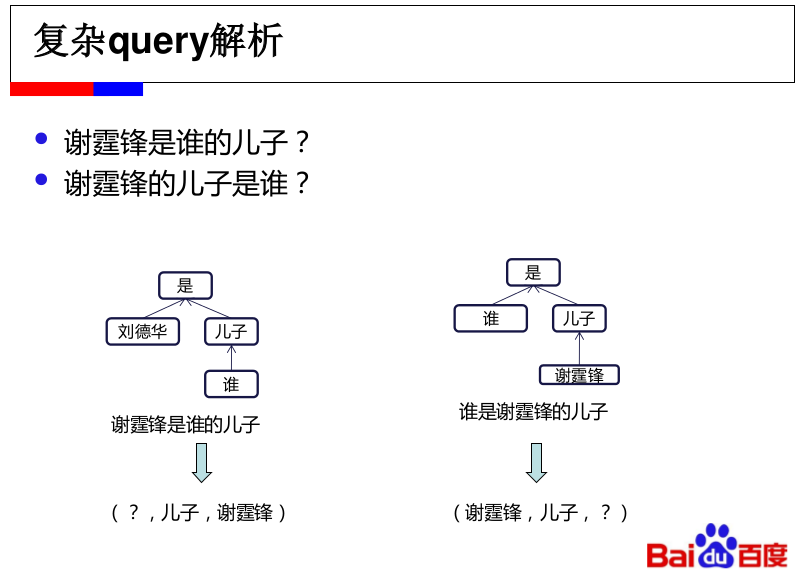
自然语言处理(Natural Language Process NLP)的相关笔记
互联网NLP应用
关于互联网NLP应用的几个截图,来自这里


计算URL链接相似度
- 网站单个页面结构分析
- 首页
- 列表页
- 内容页
-
Protocol : //[user: password]@host[:port]/path /[?query][#fragment]
(?<protocol>.*?)://(?<loginfo>(?<user>.*?):(?<pwd>.*?)@)?(?<host>[^/]+)(?:(?<path>/[^\\?#]*)(?<query>\\?[^#]+)?)?(?<frag>#.*)?
距离
- p范数和明可夫斯基距离
- 明可夫斯基距离即是p范数:
p=1,曼哈顿距离,p=2,欧氏距离,p-->无穷,切比雪夫距离
- 曼哈顿距离(来源于城市区块距离)
- 曼哈顿距离是p=1的范数:
- 切比雪夫距离
- 切比雪夫距离是的范数:
- 欧氏距离
- 欧氏距离是p=2的范数:
- 海明距离
- 在信息论中,表示两个字符串异或结果中1的个数 ###相似性
- 余弦相似度
- sim(X, Y) = cos(theta) = XY/(norm(X)norm(Y))
- 修正余弦就是另X=X-avg(X), Y=Y-avg(Y),之后再求余弦
- Jaccard距离
- Jaccard(X, Y) = (X交Y)/(X并Y)
- 皮尔森相关系数
- 衡量_线性相关_程度
- Pxy = cov(X, Y)/(cov(X,X)^0.5*cov(X,X)^0.5)
- cov(X, Y) = sum((Xi-avg(X))*(Yi-avg(Y)) for i=1 to n)/n
网页正文提取
- 基于Dom 树
- 基于网页分割找正文块
- 基于标记窗
- 基于数据挖掘和机器学习
- 基于逻辑行和最大接纳距离的网页正文提取
- 基于行块分布函数的通用网页正文抽取
- TODO 结合stopwords的正文提取
相似文本判断算法
- Shingling方法,抽取多个特征‘词汇’,通过比较特征集合的Jaccard距离(集合的交集/集合的并集)判断文档相似度
- 抽取特征词汇的方法可以使用‘停用词’,比如取每个停用词及后面k个字符作为特征词汇
- 抽取特征词汇的方法还可以使用词性,如简单地只使用名词
- I-Match算法,根据统计特性,抽取文档的主要特征进行分析 认为文档中的高频和低频词汇都不能真正反映文档的内容,所以通过IDF(出现目标词汇的文档的比例)进行过滤?TODO 求证
n-gram->language modeling->Markov property->Markov chain->Brownian motion
-
n-gram: 在计算语言学和概率论领域,n-gram是从一个给定的文字序列中提取出的n个连续文字。
n==1 –> “unigram” n==2 –> “bigram” n==3 –> “trigram” …
n-gram模型是一种概率模型,使用前面n个词对下一个词进行预测:predict xi based on x_(i-(n-1)),...,x_(i-1),数学形式:P(xi |
xi-(n-1),..,xi-1). |
当n-gram用于语言模型的时候,通常做出独立假设,比如认为每个词之和前面n-1个词相关,这样模型大大简化
-
语言模型 language modeling 统计语言模型通过概率分布的形式估计一串词的出现概率P(w1,…,wn)
-
马尔可夫性质 Markov property 满足1-gram的概率模型,认为下一个状态只受当前状态影响:the conditional probability distribution of future states of the process depends only upon the present state
-
马尔可夫链 Markov chain 一个拥有马尔可夫性质的离散过程叫做马尔可夫链
-
Brownian motion 布朗运动(Brownian motion) 过程是一种正态分布的独立增量连续随机过程。1827年英国植物学罗伯特·布朗利用一般的显微镜观察悬浮于水中由花粉所迸裂出之微粒时,发现微粒会呈现不规则状的运动,因而称它布朗运动。